داستان پویا؛ از جرقه تا تخصص در یادگیری ماشین
من «پویا»ام 😊 سه سال پیش فقط ۱۲ سالم بود و یه ویدیوی یوتیوب دیدم که کل زندگیم رو عوض کرد! همون موقع فهمیدم یادگیری ماشین خیلی باحاله و اگه بخوام توش حرفهای بشم، باید مثل یه مهندس فکر کنم. یعنی چی؟ یعنی باید بتونم هر مسئله سختی رو تیکهتیکه کنم، روش فکر کنم، امتحانش کنم و اگه اشتباه شد، ناراحت نشم.
از همون اول فهمیدم شکست، بخشی از مسیر یاد گرفتنه 💡
تو این مسیر یاد گرفتم همهچی باید با پروژه واقعی یاد گرفته بشه. نه فقط خوندن، بلکه ساختن و امتحان کردن. مثلاً وقتی پایتون یاد گرفتم، باهاش یه اسکریپت کوچیک ساختم. بعد رفتم سراغ کار با دادهها، و کمکم رسیدم به ساخت مدلهای واقعی که تو دنیای بیرون کار میکنن 😍
🔹 یادآوری مهم: این مسیر واقعاً پروژهمحوره! هر وقت به یه موضوع سخت مثل ریاضی یا الگوریتم رسیدی، فقط همونقدر یادش بگیر که بتونی پروژهات رو جلو ببری. بقیهاش خودش با تجربه جا میافته.
اینفوگرافیک مراحل یادگیری ماشین از مبتدی تا پیشرفته.
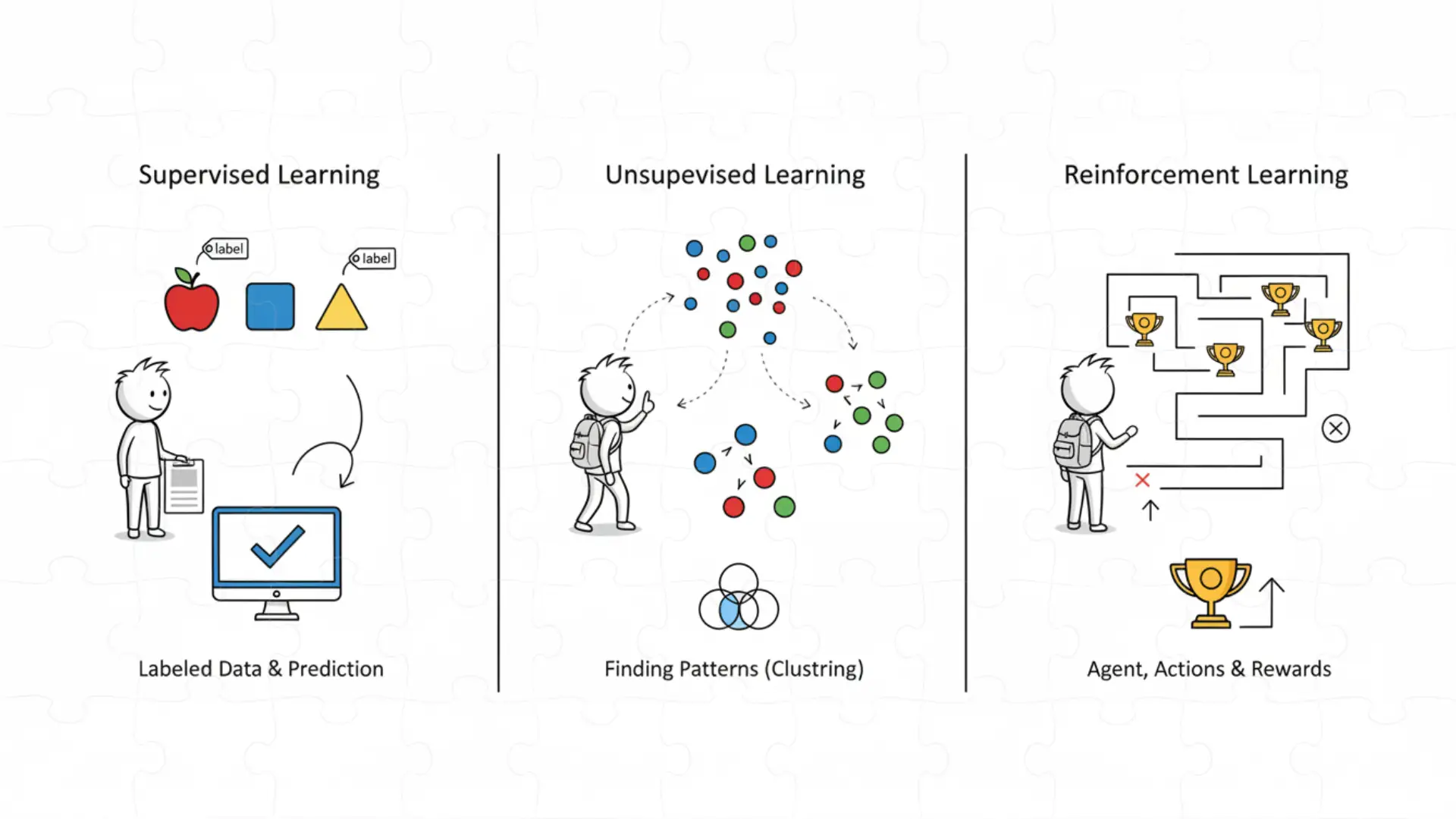
اینفوگرافیک انواع یادگیری ماشین: نظارتشده، بدون نظارت، تقویتی.
⚙️ فاز دوم: قلب یادگیری ماشین (۱۳ تا ۱۴ سالگی – سطح متوسط)
سلام دوباره! 👋
من پویام و حالا وارد یه مرحلهی جدید شدم.
اگه فاز اول مثل ساختن زمین بازی بود، فاز دوم دقیقاً شروع بازی اصلی بود! 🎯
اینجا بود که تازه فهمیدم یادگیری ماشین واقعاً یعنی چی و مدلها چطور فکر میکنن.
🤖 انواع یادگیری ماشین (Types of Machine Learning)
وقتی بیشتر یاد گرفتم، فهمیدم یادگیری ماشین سه نوع اصلی داره، و هرکدوم یه روش خاص برای یاد گرفتن از دادهها دارن:
🧩 ۱. یادگیری نظارتشده (Supervised Learning)
اینجا مدل مثل یه دانشآموزه که معلمش بهش «جواب درست» رو هم میگه 📘
یعنی دادهها برچسبدار (Labeled Data) هستن.
مثلاً من به مدل میگم:
- “این خونه ۳ تا اتاق داره، قیمتش ۸۰۰ میلیون تومنه.”
- “اون یکی خونه ۵ تا اتاق داره، قیمتش ۱.۲ میلیارد تومنه.”
مدل با دیدن این مثالها یاد میگیره قیمت خونههای جدید رو پیشبینی کنه.
به این کار میگن رگرسیون (Regression) چون خروجی عددیه (مثل قیمت 💰).
اما گاهی خروجی ما «بله یا نه» یا «این یا اون» هست.
مثلاً در پروژهٔ تایتانیک، میخوای بدونی «این نفر زنده موند یا نه؟»
به این میگن دستهبندی (Classification) چون مدل بین چند تا گزینه انتخاب میکنه ✅
🧠 ۲. یادگیری بدون نظارت (Unsupervised Learning)
اینجا دیگه معلمی نیست! 😅
مدل باید خودش توی دادهها الگو پیدا کنه.
مثلاً فرض کن یه عالمه داده از خرید مردم داری، ولی نمیدونی کی چی خریده.
مدل خودش کشف میکنه کدوم آدمها رفتار خریدشون شبیه همهست — مثلاً همهٔ کسایی که پیتزا دوست دارن معمولاً نوشابه هم میخرن 🍕🥤
به این کار میگن خوشهبندی (Clustering) و یکی از معروفترین الگوریتمهاش K-Means Clustering هست.
🕹️ ۳. یادگیری تقویتی (Reinforcement Learning)
این یکی از هیجانانگیزترین بخشهاست!
اینجا مدل مثل یه رباته که خودش تصمیم میگیره و از پاداش یا جریمه یاد میگیره ⚡
مثلاً یه ربات بازی یا ماشین مسابقه که وقتی مسیر درستی میره، امتیاز میگیره و وقتی اشتباه میره، امتیاز ازش کم میشه.
به این نوع یادگیری میگن Reinforcement Learning (RL) چون مدل خودش با «تجربه» یاد میگیره.
💻 پروژههای کاربردی با Scikit-learn
بعد از فهمیدن این مفاهیم، من رفتم سراغ پروژههای واقعی با یه کتابخونهی معروف به اسم Scikit-learn (سکیتلِرن) که مخصوص پیادهسازی الگوریتمهای یادگیری ماشینه.
🚢 پروژه تایتانیک (Titanic Survival Prediction)
اینجا هدفم این بود که بفهمم چه عواملی باعث شدن بعضی از مسافرا زنده بمونن.
ولی قبل از آموزش مدل، یه چالش بزرگ داشتم:
توی دادهها بعضی اطلاعات خالی بود 😱
مثلاً سن بعضی از مسافرا نوشته نشده بود.
من یاد گرفتم چطوری این مقادیر خالی (Missing Values) رو با عددهایی مثل میانگین (Mean)، میانه (Median) یا مد (Mode) پر کنم.
به این کار میگن Imputation (جایگزینی دادههای گمشده).
یه کار باحال دیگه هم کردم: ساختم ویژگی (Feature) جدید.
مثلاً یه ستون درست کردم به اسم «اندازه خانواده» که از جمع تعداد خواهر و برادر و والدین ساخته میشد.
این باعث شد مدل بهتر بفهمه چه کسایی شانس بیشتری برای بقا داشتن.
🏠 پروژه پیشبینی قیمت خانه (House Price Prediction)
اینجا وارد دنیای رگرسیون (Regression) شدم.
یعنی مدل من باید یه عدد رو پیشبینی میکرد (قیمت خونه 💰).
فرمول سادهش این بود:
Y = mX + c
که توش Y قیمت خونهست، X تعداد اتاقها، و m و c عددهاییه که مدل یاد میگیره.
وقتی ورودیها زیاد میشن (مثلاً علاوه بر اتاق، سن خونه، محله، و اندازه زمین هم مهم میشن)، مدل از یه خط ساده تبدیل میشه به یه صفحه سهبعدی (Plane) — که بهش میگن رگرسیون چندگانه (Multiple Regression).
🧹 مدیریت داده (Data Cleaning) – ستون فقرات یادگیری ماشین
من خیلی زود فهمیدم که مدل خوب فقط با دادهٔ تمیز ساخته میشه.
یه جمله معروف هست که میگه:
“Garbage in, garbage out”
یعنی اگه دادههات آشغال باشن، خروجی مدل هم آشغال درمیاد 😅
✴️ مدیریت دادههای گمشده (Missing Values):
اگه یه ستون از داده خالی باشه، مدل نمیتونه باهاش کار کنه.
برای همین با استفاده از روش Imputation عددهایی مثل میانگین (Mean) رو جایگزینش میکردم.
⚡ نقاط پرت (Outliers):
گاهی توی داده یه مقدار خیلی عجیب هست (مثلاً حقوق ۱۰۰ میلیون بین بقیه که ۵ میلیون دارن 💸).
این نقاط باعث میشن مدل اشتباه کنه.
برای پیدا کردنشون از نمودار Box Plot (نمودار جعبهای) و روش IQR (Interquartile Range) استفاده کردم.
📏 مقیاسبندی دادهها (Scaling):
بعضی ویژگیها مقدارشون بزرگتره (مثلاً «حقوق» چند میلیون تومنه ولی «سن» فقط چند ساله).
مدل ممکنه فکر کنه حقوق مهمتره چون عددش بزرگتره، در حالی که این اشتباهه.
برای حلش از روشهایی مثل Standard Scaler یا Min-Max Scaler استفاده کردم تا همهٔ عددها تو یه محدوده باشن.
🔤 کدگذاری دادههای متنی (Encoding):
مدل فقط عدد میفهمه، نه کلمه.
مثلاً اگه ستون «شهر» داشته باشیم (تهران، مشهد، اصفهان)، باید اونها رو به عدد تبدیل کنیم.
برای این کار از دو روش استفاده میکردم:
- Label Encoding: هر دسته یه عدد میگیره (تهران=۱، مشهد=۲، اصفهان=۳).
- One-Hot Encoding: برای هر شهر یه ستون جدا ساخته میشه با صفر و یک (۰=نیست، ۱=هست).
🧩 جلوگیری از یادگیری بیشازحد (Overfitting)
یکی از چیزایی که توی این فاز یاد گرفتم، این بود که مدل نباید فقط «حافظه» داشته باشه!
یعنی نباید فقط دادههای آموزش رو حفظ کنه و روی دادههای جدید خراب عمل کنه 😅
✂️ Train/Test Split:
یاد گرفتم دادهها رو به دو بخش تقسیم کنم:
- Train Set (مجموعه آموزش): برای یاد دادن به مدل.
- Test Set (مجموعه آزمایش): برای امتحان مدل روی دادههایی که ندیده.
اینطوری فهمیدم مدل واقعاً یاد گرفته یا فقط حفظ کرده.
📉 تابع هزینه و گرادیان کاهشی (Cost Function & Gradient Descent):
تابع هزینه (Cost Function) یه عدد به مدل میده که نشون میده چقدر اشتباه کرده.
مدل با یه روش باحال به نام گرادیان کاهشی (Gradient Descent) سعی میکنه اون اشتباه رو کمکم کمتر کنه.
یعنی در هر مرحله وزنها (Weights) رو یهذره تغییر میده تا خطا (Error) کمتر بشه.
یه چیزی مثل یاد گرفتن دوچرخهسواریه 🚲 هر بار که میافتی، بهتر میشی!
✨ نتیجهی فاز دوم؟
در ۱۴ سالگی تازه فهمیدم مدلها چطوری یاد میگیرن و چطور میشه بهشون اعتماد کرد.
دیگه فقط یه کدنویس نبودم، یه طراح مدل هوش مصنوعی (AI Model Designer) شده بودم 🤖
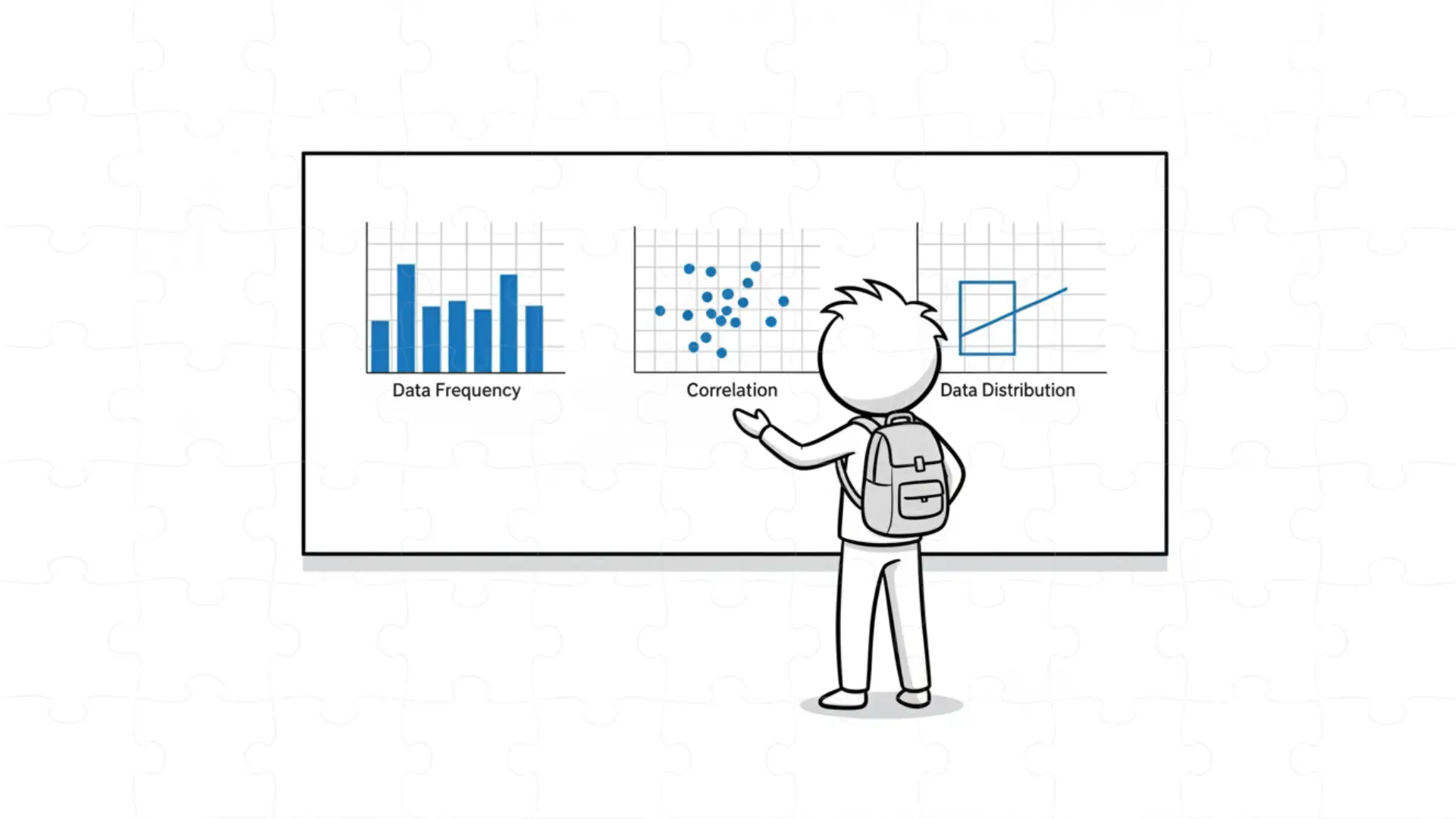
تحلیل اکتشافی داده با نمودارهای ساده.
🚀 فاز سوم: متخصص شدن در یادگیری ماشین (۱۵ سالگی – سطح پیشرفته)
خب، حالا که یاد گرفتم چطور داده رو تمیز کنم و مدلهای ساده بسازم، وقتش بود یادگیری ماشین واقعی رو تجربه کنم — اونجایی که مدلها خودشون یاد میگیرن فکر کنن 🤯
🧮 قدم اول: یاد گرفتن الگوریتمهای پیشرفته (Advanced Algorithms)
در این مرحله، یاد گرفتم بعضی مدلها میتونن از خطوط ساده (Linear Models) جلوتر برن و رابطههای پیچیدهتری یاد بگیرن.
اینا چندتا از مهمترین چیزایی هستن که یاد گرفتم 👇
🌈 رگرسیون چندجملهای (Polynomial Regression):
تو رگرسیون خطی ساده، مدل یه خط مستقیم رسم میکنه، ولی دنیا همیشه صاف نیست!
گاهی دادهها منحنیان 😅
مثلاً قد و وزن یا دما و فروش بستنی، همیشه خطی نیستن.
Polynomial Regression کمک میکنه مدل بتونه منحنی یاد بگیره — مثلاً با استفاده از (X^2) یا (X^3).
این باعث میشه پیشبینی دقیقتر بشه 🎯
🧠 شبکههای عصبی (Neural Networks):
وای این قسمت واقعاً جادوی یادگیری ماشینه ✨
من یاد گرفتم چطور یه شبکهٔ عصبی رو از صفر بسازم (بدون استفاده از کتابخونههایی مثل TensorFlow یا PyTorch).
اولش سخت بود، ولی وقتی فهمیدم چی داره پشت صحنه اتفاق میافته، همهچی برام مثل یه فیلم علمیتخیلی شد!
Neural Network (NN) یعنی یه سیستم از «نورونهای مصنوعی» که داده رو مرحلهبهمرحله پردازش میکنن تا الگوها رو یاد بگیرن.
یه چیز باحال هم یاد گرفتم:
برای اینکه شبکه یاد بگیره، باید اشتباهاتش رو بفهمه و خودش رو اصلاح کنه.
به این میگن پسانتشار خطا (Backpropagation) که با کمک گرادیان کاهشی (Gradient Descent) وزنهای شبکه رو بهبود میده تا خطا کم بشه 🔁
مثال ساده:
من یه شبکه ساختم که یاد بگیره دستنوشتههای اعداد ۰ تا ۹ رو تشخیص بده (مثل اپلیکیشنهای تشخیص عدد).
وقتی مدل اشتباه میگفت، وزنهاش تنظیم میشدن تا دفعه بعد بهتر حدس بزنه.
🌀 دستهبندی غیرخطی (Non-Linear Classification):
یاد گرفتم بعضی دادهها رو نمیشه با یه خط جدا کرد.
مثلاً دایرههایی که یکی توی دیگریه 🎯
برای این موارد از الگوریتمهایی مثل ماشین بردار پشتیبان (Support Vector Machine – SVM) یا رگرسیون لجستیک چندجملهای (Multinomial Logistic Regression) استفاده کردم.
اینا میتونن مرزهای پیچیدهتری بین دادهها رسم کنن.
🧩 قدم دوم: حرفهای شدن در ساخت مدلها (Feature Engineering & Optimization)
⚙️ مهندسی ویژگی (Feature Engineering):
یاد گرفتم یکی از مهمترین کارها اینه که دادههام رو طوری تغییر بدم که مدل بهتر بفهمه.
مثلاً یه تاریخ مثل ۲۰۲۵-۱۰-۲۷ رو میشه به «سال»، «ماه» و «روز هفته» تقسیم کرد.
این کار باعث میشه مدل بفهمه مثلاً در روزهای تعطیل فروش بیشتره! 📆
خیلی وقتا این قسمت باعث میشد دقت مدل من ۲۰٪ بهتر بشه 😲
🎯 تنظیم پارامترهای مدل (Hyperparameter Tuning):
یاد گرفتم هر مدل یه سری دکمه و تنظیم داره که میتونی با تغییرشها دقت مدل رو بالا ببری.
مثلاً توی درخت تصمیم (Decision Tree) عمق درخت (Tree Depth) خیلی مهمه.
یا توی شبکههای عصبی (Neural Networks)، تعداد نورونها و نرخ یادگیری (Learning Rate).
برای پیدا کردن بهترین ترکیب، از روشهایی مثل:
- Grid Search: امتحان کردن همه حالتهای ممکن 🔍
- Random Search: امتحان کردن چند حالت تصادفی (سریعتر از قبلی).
🧱 رگولاریزاسیون (Regularization):
بعضی وقتا مدل خیلی پیچیده میشه و میخواد هر دادهای رو کامل حفظ کنه — به این میگن Overfitting.
برای جلوگیریش از Regularization استفاده کردم.
دو نوع معروف داره:
- Lasso (L1 Regularization): وزنهای غیرمهم رو دقیقاً صفر میکنه (پس مدل سادهتر میشه).
- Ridge (L2 Regularization): وزنها رو کوچیکتر میکنه، ولی صفر نه — باعث پایداری مدل میشه.
🧠 قدم سوم: پروژههای واقعی در سطح حرفهای (Advanced ML Projects)
حالا نوبت این بود که مدلهام رو در پروژههای دنیای واقعی امتحان کنم 🔥
🎬 سیستمهای توصیهگر (Recommendation Systems):
حتماً دیدی وقتی یه ویدیو توی یوتیوب یا یه فیلم توی نتفلیکس نگاه میکنی، خودش چندتا پیشنهاد مشابه میده؟ 🎥
اونها از Recommendation System استفاده میکنن.
من یاد گرفتم دوتا روش داره:
- Collaborative Filtering: بر اساس رفتار بقیه کاربرا پیشنهاد میده.
- Content-based Filtering: بر اساس ویژگیهای خود چیزهایی که دوست داری.
👁️ بینایی کامپیوتر (Computer Vision):
یکی از خفنترین پروژههام ساخت یه سیستم تشخیص چهره (Face Recognition) بود 😎
با استفاده از شبکه عصبی کانولوشنی (Convolutional Neural Network – CNN) تونستم تشخیص بدم توی یه عکس کی حضور داره.
مثلاً وقتی جلوی دوربین لبخند میزدم، مدل میگفت: “پویا خوشحاله!” 😁
💬 پردازش زبان طبیعی (Natural Language Processing – NLP):
اینجا وارد دنیای متن شدم ✍️
مدلی ساختم که بتونه تشخیص بده یه جمله مثبت، منفی یا خنثیه (بهش میگن تحلیل احساسات – Sentiment Analysis).
حتی با اموجیها هم تمرین کردم 😅
بعدش با مدلهای بزرگتر مثل Transformer آشنا شدم، که همون چیزیه که مدلهای بزرگی مثل ChatGPT ازش استفاده میکنن 🧠✨
📊 قدم چهارم: ارزیابی دقیق مدلها (Model Evaluation)
فهمیدم فقط دقت (Accuracy) کافی نیست.
گاهی یه مدل با دقت ۹۸٪ میتونه اشتباههای خطرناکی کنه 😬
پس یاد گرفتم از معیارهای بهتر استفاده کنم.
🧾 ماتریس درهمریختگی (Confusion Matrix):
یه جدول کوچیک که نشون میده مدل چند تا جواب درست داده و چند تا اشتباه.
مثلاً چند نفر رو سالم گفته که واقعاً سالم بودن (True Positive)، یا اشتباه تشخیص داده (False Negative).
🔢 معیارهای اصلی:
- Precision (دقت): چند تا از پیشبینیهای مثبت درست بودن.
- Recall (فراخوانی): مدل چند تا از موارد واقعی رو درست پیدا کرده.
- F1 Score: ترکیبی از Precision و Recall برای نتیجه بهتر.
⚖️ دادههای نامتوازن (Imbalanced Data):
مثلاً اگه فقط ۲٪ دادهها مربوط به تقلب باشن، مدل ممکنه همیشه بگه “تقلب نیست” و دقتش بالا باشه ولی در واقع بیفایدهست!
من یاد گرفتم با Resampling (نمونهگیری دوباره) دادهها رو متعادل کنم.
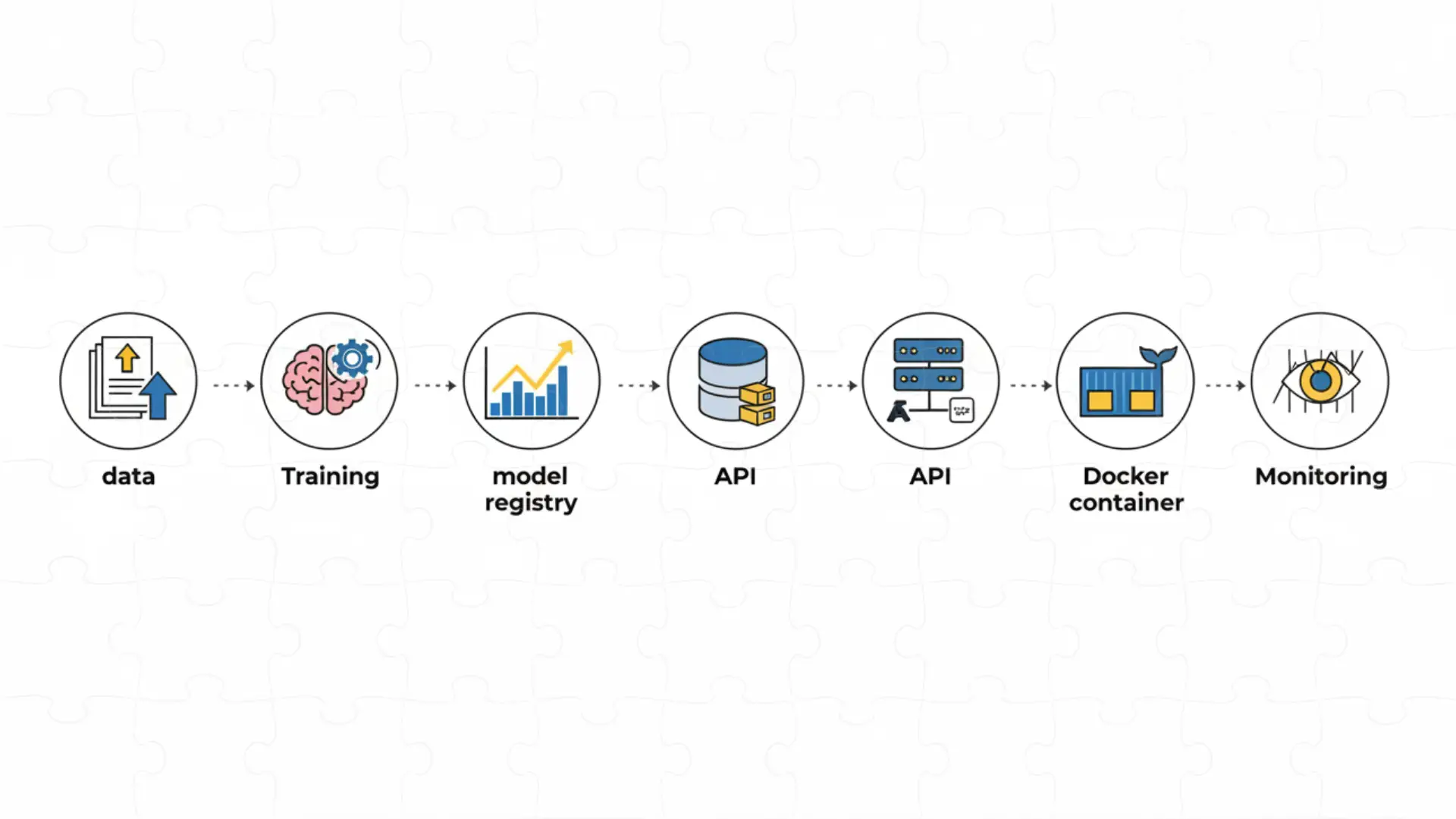
🧰 قدم پنجم: ساخت و استقرار مدلها (MLOps & Deployment)
آخرش یاد گرفتم ساخت مدل فقط نصف کاره — نصف دیگهش اینه که مدلهام رو در دنیای واقعی اجرا کنم! 🌍
🧱 MLOps (Machine Learning Operations):
یعنی مدیریت کل چرخهٔ مدل: از آموزش گرفته تا نگهداری، مانیتورینگ، و آپدیت خودکار.
مدلهایی ساختم که خودشون وقتی دقتشون افت میکرد، دوباره آموزش میدیدن 😲
⚙️ استقرار (Deployment):
برای اینکه بقیه هم بتونن از مدلهام استفاده کنن، با ابزارهایی مثل:
- Flask و Django: برای ساخت وبسرویسهایی که مدل رو به سایت یا اپلیکیشن وصل میکنن.
- Docker: برای بستهبندی مدل و اجرا در هر کامپیوتر یا سرور.
- A/B Testing: برای مقایسه دو مدل و دیدن کدوم عملکرد بهتری داره.
✨ نتیجهی فاز سوم؟
من توی ۱۵ سالگی یاد گرفتم فقط مدل نسازم، بلکه یه سیستم هوشمند واقعی بسازم — مدلی که کار کنه، یاد بگیره و توی دنیای واقعی نتیجه بده 💡
حالا دیگه فقط یه دانشآموز نبودم، یه متخصص یادگیری ماشین (Machine Learning Specialist) بودم که میتونست از صفر تا صد یه پروژهٔ هوش مصنوعی رو بسازه! 🤖💪
استقرار مدل یادگیری ماشین با Docker و وبسرویس.
نقشه راه پروژهمحور: از Beginner تا Advanced
جدول مهارتها و پروژهها (بر اساس گزارش)
سوالات متداول (FAQ)
- machine learning چیست؟
یادگیری ماشین شاخهای از هوش مصنوعی است که مدلها از دادهها الگو میگیرند تا پیشبینی یا تصمیمگیری کنند. - انواع یادگیری ماشین کداماند؟
نظارتشده، بدون نظارت و تقویتی—هرکدام برای مسئلهای متفاوت بهکار میروند. - مراحل یادگیری ماشین بهصورت عملی چیست؟
شروع با Python و EDA، سپس پروژههای Scikit-learn و مدیریت داده، بعد تکنیکهای پیشرفته و نهایتاً استقرار (MLOps/Deployment). - ماشین لرنینگ بدون ریاضی عمیق ممکن است؟
بله؛ بهاندازهٔ نیاز پروژه ریاضی یاد بگیرید و در طول مسیر عمیق شوید. - چطور جلوی Overfitting را بگیریم؟
Train/Test Split، Regularization، کنترل Hyperparameterها و مهندسی ویژگی. - برای استخدام/کار واقعی چه چیزی مهمتر است؟
پروژههای مستند، پورتفولیو، توانایی استقرار و حل مسئله—نه صرفاً مدرک.
جمعبندی: چگونه مثل پویا «جادوگر هوش مصنوعی» شویم
میدونی راز من چیه؟
خیلی سادهست: پروژهمحور کار کن، دادههاتو تمیز نگه دار، نتایج رو اندازهگیری کن و بعد مدلهاتو استقرار بده.
من از پروژههای کوچیکی مثل تحلیل داده (EDA) و دستهبندی گل زنبق (Iris Classification) شروع کردم، با پروژههای تایتانیک (Titanic Survival) و پیشبینی قیمت مسکن (House Price Prediction) قویتر شدم، بعدش رفتم سراغ ساخت مدلهای واقعی مثل شبکههای عصبی (Neural Networks)، سیستمهای توصیهگر (Recommendation Systems)، بینایی کامپیوتر (Computer Vision) و پردازش زبان طبیعی (NLP).
در نهایت فهمیدم که دنیای Machine Learning وقتی واقعی میشه که بتونی با MLOps و Docker مدلهاتو وارد محیط تولید کنی و در دنیای واقعی اجراشون ببینی 🚀
اما مهمترین چیزی که یاد گرفتم اینه:
شکست خوردن بخشی از مسیر موفقیته — مخصوصاً توی یادگیری ماشین (Machine Learning).
هر بار که مدل اشتباه میکرد، من نه ناامید، بلکه هیجانزده میشدم چون میدونستم یه قدم به درک واقعی Machine Learning چیست نزدیکتر شدم 💡
اگه تو هم میخوای مثل من مسیرت رو از صفر تا صد یادگیری ماشین بسازی، پیشنهاد میکنم حتماً یه سر به 🔗 موبوش بزنی — اینجا پر از آموزشهای پروژهمحور و کاربردی دربارهی هوش مصنوعی، یادگیری ماشین، و مدلهاست.


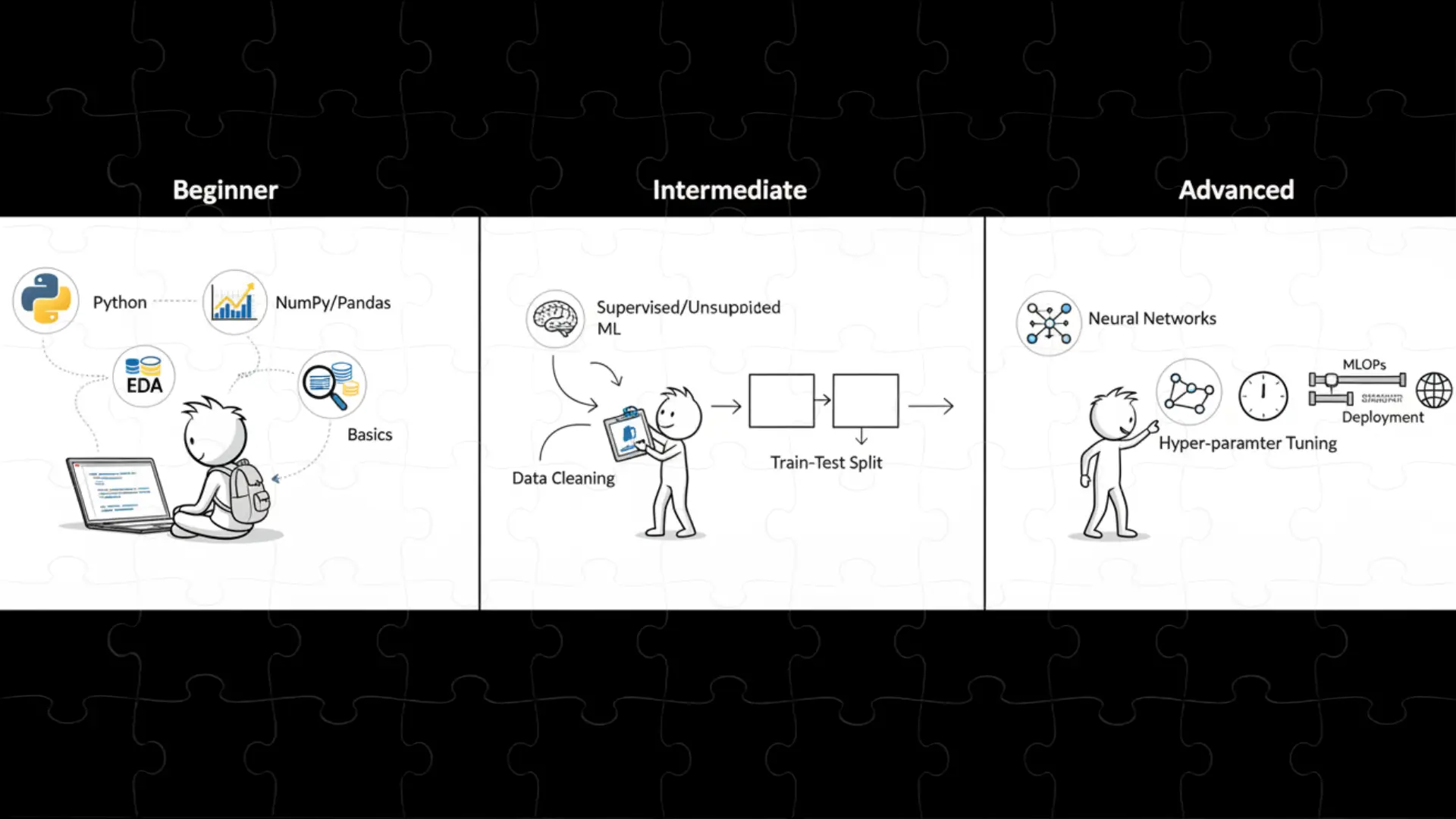
 فاز اول: شروع قوی (وقتی ۱۲ سالم بود – سطح مبتدی)
فاز اول: شروع قوی (وقتی ۱۲ سالم بود – سطح مبتدی) فاز اول: شروع قوی (وقتی ۱۲ سالم بود – سطح مبتدی)
فاز اول: شروع قوی (وقتی ۱۲ سالم بود – سطح مبتدی)
 قدم اول: یاد گرفتن پایتون (Python) – زبون جادویی برنامهنویسا
قدم اول: یاد گرفتن پایتون (Python) – زبون جادویی برنامهنویسا

 ابزارهایی که مثل ابرقدرت بودن! (
ابزارهایی که مثل ابرقدرت بودن! (

 ریاضی به اندازهای که واقعاً لازم بود
ریاضی به اندازهای که واقعاً لازم بود

 نکته طلایی پویا:
نکته طلایی پویا: پروژههای اولین مرحله یادگیری من
پروژههای اولین مرحله یادگیری من
 )
)

 نتیجهی فاز اول؟
نتیجهی فاز اول؟